Run LLMs on Cloud Run with GPUs
Cloud Run as of today became one of the very few services to offer GPUs on a serverless product. It allows you to use one L4 GPU per Cloud Run instance, which as of today has NVIDIA driver version: 535.129.03 (CUDA 12.2).
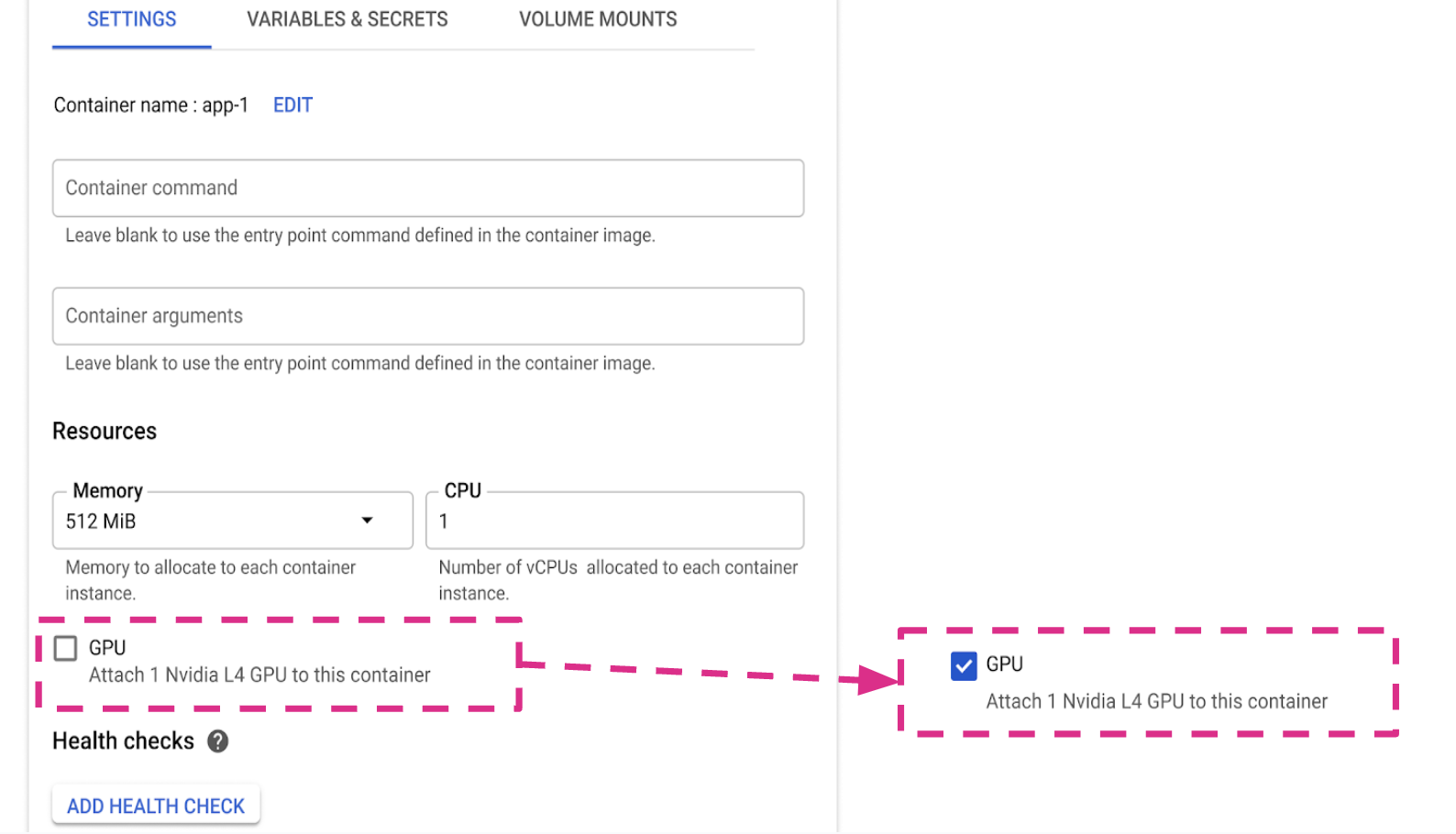 GPU Option in Cloud Run
GPU Option in Cloud Run
This will be helpful for a lot of Gen AI Use Cases such as:
Real-time AI inference and prediction with lightweight open-source models like Gemma 2B/9B, Phi3, Llama models etc..
Serving custom fine-tuned LLMs.
Additional compute intensive workloads such as image recognition, online gaming, video transcoding and streaming, and more.
In this article, I’ll show how to quickly build a playground to run open-source LLMs of a certain size and test/serve them out using LangChain, LangServe and Ollama. Let’s start with Ollama:
Ollama
Ollama is a platform that makes it easy to run large language models (LLMs) locally on your computer. It simplifies the process of installing and managing LLMs by providing a user-friendly interface and pre-configured models.
Key features
Pre-configured models: Ollama comes with a variety of pre-configured models that you can use out of the box.
Customizable: You can customize the models to fit your specific needs.
Let’s pack Ollama in a docker image and download some models right into the image. In this case, we download Gemma, Phi and Llama, but any model supported by Ollama can be downloaded.
1
2
3
4
5
6
7
8
9
10
11
12
13
FROM ollama/ollama:0.2.0
ENV OLLAMA_HOST 0.0.0.0:8080
ENV HOME /root
ENV OLLAMA_MODELS /models
ENV OLLAMA_DEBUG false
RUN apt-get update && apt-get install netcat -y
COPY download-models.sh /
RUN ./download-models.sh
CMD ["serve"]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# Function to check if ollama serve is listening on port 8080
wait_for_ollama() {
while ! nc -z localhost 8080; do
sleep 1 # Wait 1 second before checking again
done
}
# Start ollama serve in the background
ollama serve &
# Wait for ollama serve to start listening
wait_for_ollama
echo "ollama serve is now listening on port 8080"
# Run ollama pull
ollama pull gemma2:2b
ollama pull phi3:mini
ollama pull llama3.1:8b
# Indicate successful completion
echo "Local LLMs downloaded!"
This will work as our backend. Let’s work on our frontend using LangChain and LangServe. But first, a quick introduction:
LangChain is a framework that simplifies building applications using language models by chaining together different steps, tools, and data sources. It enables developers to create complex, multi-step NLP workflows with integrated memory and agent systems.
LangServe is an extension of LangChain that focuses on deploying and serving language models as APIs or services. It allows developers to take the chains or applications they have built using LangChain and expose them as web services that can be easily integrated into other applications or accessed by users.
Now, it’s time for some code. The following setup creates two chains for Gemma and Phi respectively, using Ollama backend running locally or on a cloud run service through the dockerfile we created earlier. Next, these chains are exposed through HTTP-routes using LangServe.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
import os
from fastapi import FastAPI
from langchain_community.llms import Ollama
from langchain.prompts import PromptTemplate
from langserve import add_routes
import uvicorn
OLLAMA_URL = os.environ.get("OLLAMA_SERVICE", "http://localhost:11434")
print(f"Ollama URL - {OLLAMA_URL}")
phi = Ollama(model="phi3:mini", base_url=OLLAMA_URL, verbose=True)
template = PromptTemplate.from_template("{question}")
phi_chain = template | phi
gemma = Ollama(model="gemma2:2b", base_url=OLLAMA_URL, verbose=True)
gemma_chain = template | gemma
app = FastAPI(title="Local LLMs using Ollama", version="1.0", description="Local LLMs using Ollama")
add_routes(app, phi_chain, path="/phi")
add_routes(app, gemma_chain, path="/gemma")
if __name__ == "__main__":
uvicorn.run(app, host="localhost", port=8000)
The complete code can be found here including a Makefile and Dockerfile for the frontend to ease the deployment on Cloud Run.
Running locally
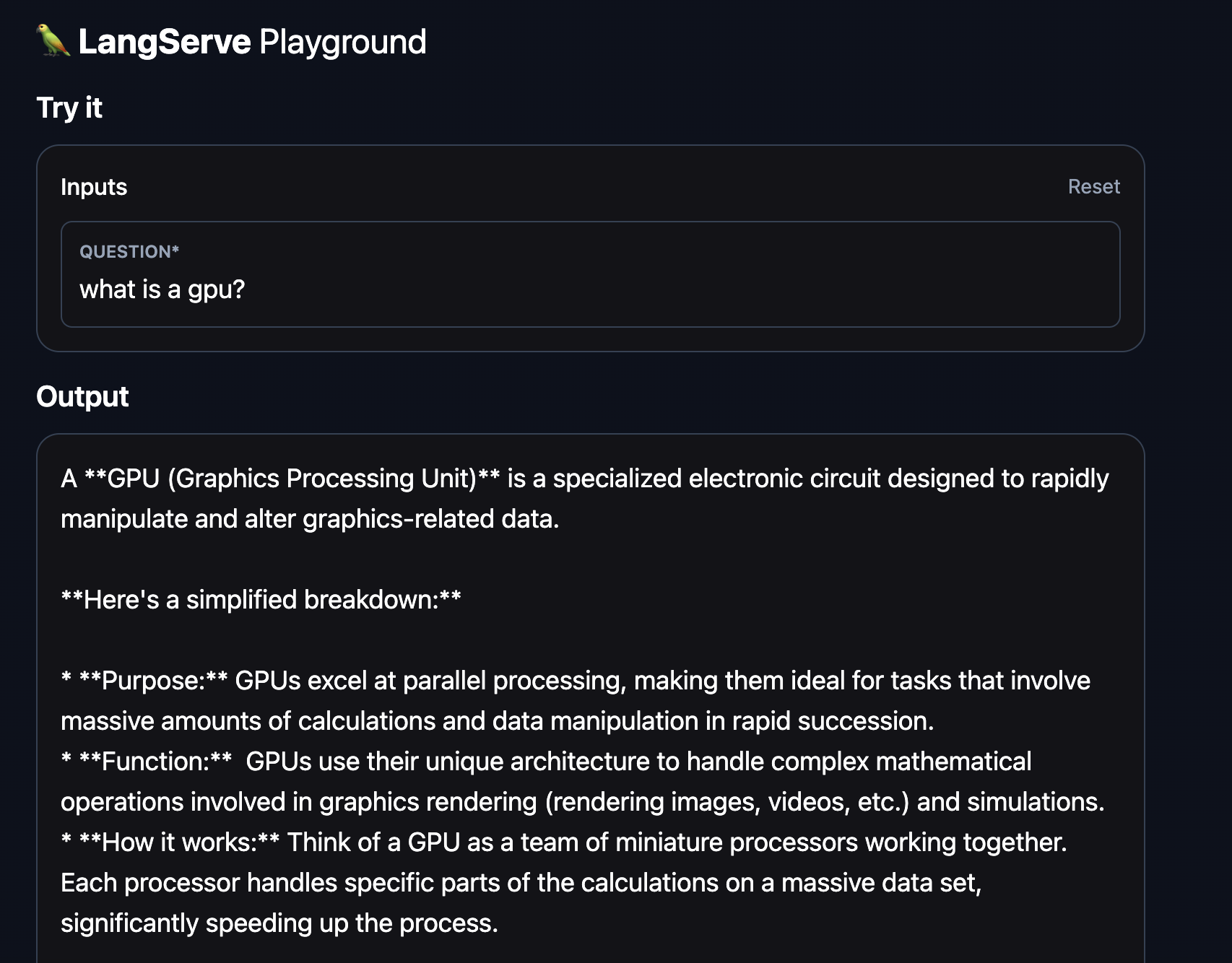 LangServe Gemma example
LangServe Gemma example
Start the Ollama server and pull the models we defined LLM Chains for in the LangServe Frontend. Next, start the LangServe endpoint.
1
2
3
4
5
6
7
8
# Ollama Backend
ollama serve
ollama pull gemma2:2b
ollama pull phi3:mini
# LangServe Frontend
cd langchain-local-llms/
make start
Tips for running on Cloud Run
- CPU must be configured to CPU always allocated.
- Configure a minimum of 4 CPU for your service, with 8 CPU recommended.
- Configure a minimum of 16 GiB of memory, with 32 GiB recommended.
- Determine and set an optimal maximum concurrency for your GPU usage.
- Maximum instances must be set to a number that is below the allowed quota for GPU.
- Requires the second generation execution environment, or use the default environment.